5 марта 2025 года компания Alibaba представила новую большую языковую модель (LLM) с открытым исходным кодом - QwQ-32B. Модель доступна как для коммерческого, так и для исследовательского использования, позволяя компаниям напрямую интегрировать ее в продукты и приложения, в том числе платные. QwQ, сокращение от Qwen-with-Questions - это модель рассуждений с открытым исходным кодом, впервые представленная Alibaba в ноябре 2024 года с целью конкурировать с o1-preview от OpenAI. Оригинальная QwQ улучшила свои возможности логического мышления и планирования, особенно в математических и кодовых задачах, путем анализа и уточнения собственных ответов в процессе рассуждений. Предыдущая версия QwQ имела 32 миллиарда параметров и длину контекста 32 000 токенов, превосходя o1-preview в математических бенчмарках, таких как AIME и MATH, и задачах научного мышления, таких как GPQA.
Несмотря на то, что QwQ-32B имеет всего 32 миллиарда параметров, она демонстрирует производительность, сопоставимую с DeepSeek-R1, моделью с 671 миллиардом параметров. Alibaba заявляет, что QwQ-32B превосходит OpenAI o1-mini и конкурирует с DeepSeek-R1 по производительности в задачах, связанных с математическими рассуждениями, кодированием и общим решением проблем. Этот прорыв подчеркивает потенциал масштабирования обучения с подкреплением (RL) на надежных базовых моделях, предварительно обученных на обширных мировых знаниях.
Ключевые особенности QwQ-32B
QwQ-32B - это причинно-следственная языковая модель, построенная с использованием передовой архитектуры Transformer. Она включает в себя RoPE, SwiGLU, RMSNorm и Attention QKV bias. С 64 слоями и конфигурацией внимания из 40 голов для запросов и 8 для пар ключ-значение, она оптимизирована для задач, требующих глубоких рассуждений. Ее расширенная длина контекста в 32 768 токенов позволяет модели обрабатывать большие входные данные и решать сложные многоступенчатые задачи.
Обучение с подкреплением
Ключевым нововведением в QwQ-32B является интеграция обучения с подкреплением (RL) в процесс обучения. Вместо того чтобы полагаться исключительно на традиционные методы предварительного обучения, модель проходит корректировки на основе RL, которые направлены на повышение производительности в конкретных областях, таких как математика и кодирование. Используя вознаграждения, основанные на результатах, которые проверяются с помощью проверок точности и тестов выполнения кода, модель постоянно совершенствует свои выходные данные. Этот адаптивный подход повышает ее способности к решению задач и помогает ей более эффективно обобщать информацию в различных задачах.
Процесс обучения с подкреплением в QwQ-32B разделен на два этапа: первый фокусируется на математических и кодовых способностях, обучение с верификатором точности и сервером выполнения кода. Второй этап расширяется до общих возможностей, включая вознаграждения от общих моделей вознаграждения и верификаторов на основе правил.
Агентные возможности
QwQ-32B также обладает агентскими возможностями, динамически корректируя свой процесс рассуждений на основе обратной связи с окружающей средой. Команда Qwen успешно интегрировала агентные возможности в модель рассуждений, позволяя ей критически мыслить, использовать инструменты и адаптировать свои рассуждения на основе обратной связи с окружающей средой. «Масштабирование RL может повысить производительность модели за пределы традиционных методов предварительного обучения и последующего обучения», - заявила команда. «Недавние исследования показали, что RL может значительно улучшить возможности рассуждений моделей».
Команда Qwen рекомендует использовать определенные настройки рассуждений для оптимальной производительности и поддерживает развертывание с помощью vLLM
Сравнение QwQ-32B с другими моделями
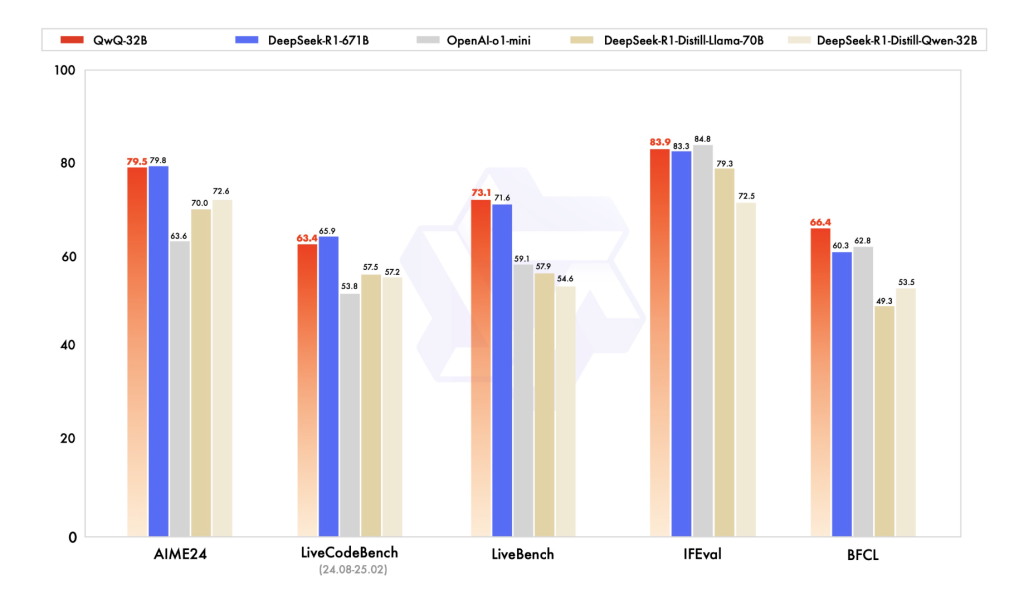
QwQ-32B продемонстрировала конкурентоспособные результаты в сравнении с другими ведущими моделями, такими как DeepSeek-R1, o1-mini и DeepSeek-R1-Distilled-Qwen-32B, несмотря на то, что имеет меньше параметров, чем некоторые конкуренты. Например, DeepSeek-R1 имеет 671 миллиард параметров (37 миллиардов активированных), в то время как QwQ-32B обеспечивает сопоставимую производительность при значительно меньших требованиях к VRAM, обычно требуя 24 ГБ на GPU, по сравнению с DeepSeek R1, которому требуется более 1500 ГБ.
Модель была протестирована на различных бенчмарках, включая AIME24, LiveCodeBench, LiveBench, IFEval и BFCL, разработанных для оценки ее математических рассуждений, навыков кодирования и общих способностей к решению задач.
AIME: American Invitation Mathematics Evaluation, который проверяет решение математических задач с помощью арифметики, алгебры, подсчета, геометрии, теории чисел, вероятности и других математических тем средней школы.
MATH-500: 500 тестовых случаев бенчмарка MATH, всеобъемлющего набора данных, проверяющего решение математических задач.
GPQA: Graduate-Level Google-Proof Q&A Benchmark, сложный бенчмарк для оценки способностей к решению научных задач с помощью вопросов уровня начальной школы.
LiveCodeBench: сложный бенчмарк для оценки способностей к генерации кода и решению задач в реальных сценариях программирования.
Сравнение бенчмарков ИИ-моделей
| Benchmark | QwQ-32B | DeepSeek-R1 | o1-mini |
|---|---|---|---|
| AIME24 | 79.5 | 79.8 | 63.6 |
| LiveCodeBench | 63.4 | 65.9 | 53.8 |
| LiveBench | 73.1 | 71.6 | 57.5 |
| IFEval | 83.9 | 83.3 | 59.1 |
| BFCL | 66.4 | 62.8 | 49.3 |
Анализ конкурентов
Для лучшего понимания позиции QwQ-32B на рынке больших языковых моделей, проведем анализ ее основных конкурентов:
- DeepSeek R1: Эта модель, разработанная DeepSeek, обладает высокой производительностью в задачах рассуждения и математики, конкурируя с моделями A1 от OpenAI. Она также хорошо справляется со структурированными вопросами и ответами, часто превосходя A1. DeepSeek R1 выделяется тем, что обучалась только с помощью обучения с подкреплением (RL) без контролируемой тонкой настройки (SFT). Это позволило ей развить сильные способности к рассуждению, но привело к некоторым недостаткам, таким как смешивание языков в ответах и менее отточенные выходные данные по сравнению с чат-моделями, такими как GPT от OpenAI. DeepSeek R1 также уязвима для джейлбрейка, атак с внедрением подсказок, генерации вредоносного ПО и других угроз безопасности.
- Sonnet 3.7: Эта модель от Anthropic обладает гибридными возможностями рассуждения, что позволяет ей выдавать как мгновенные результаты, так и расширенные пошаговые рассуждения. Она хорошо понимает контекст и инструкции, исправляет ошибки и создает сложный анализ на основе данных. Sonnet 3.7 также имеет большое контекстное окно (200 000 токенов) и низкий уровень галлюцинаций. Однако при работе с большими базами кода Sonnet 3.7 может сталкиваться с проблемами дублирования, путаницы и неэффективной обработки нескольких файлов.
- GPT-4.5: Эта модель от OpenAI отличается высокой точностью, эмоциональной глубиной и развитыми способностями к рассуждению. Она хорошо подходит для решения сложных задач, требующих детального мышления и творчества. GPT-4.5 также имеет более широкую базу знаний и более естественный стиль общения по сравнению с GPT-4o. Однако она не выполняет детальную пошаговую логику, как модели серии o, и может быть медленнее из-за своего размера.
- GROK 3: Эта модель от xAI отличается высокой вычислительной мощностью, что позволяет ей быстро и точно отвечать на вопросы. Она превосходит GPT-4 и DeepSeek V3 в тестах по математике, науке и кодированию. GROK 3 также имеет доступ к данным в режиме реального времени благодаря интеграции с X (ранее Twitter). Однако она имеет ограниченную поддержку сообщества и более крутую кривую обучения по сравнению с ChatGPT.
- o1: Эта модель от OpenAI хорошо справляется с задачами кодирования, но может испытывать трудности с очень сложными или нишевыми задачами кодирования, требующими глубоких знаний в конкретной области.
- o3-mini: Эта модель от OpenAI предлагает три различных уровня рассуждений: низкий, средний и высокий. Низкий уровень рассуждений обеспечивает быстрые ответы, средний - баланс между скоростью и точностью, а высокий - высокую точность для сложных задач. o3-mini также является экономически эффективным решением. Однако она может испытывать трудности со сложными рассуждениями и может неожиданно терять контекст.
Сильные и слабые стороны QwQ-32B
Сильные стороны:
- Высокая производительность в задачах, требующих глубоких рассуждений, особенно в математике и кодировании.
- Итеграция обучения с подкреплением, что позволяет модели динамически адаптироваться и улучшать свои результаты.
- Открытый исходный код, предоставляющий исследователям и разработчикам доступ к модели для изучения и дальнейшего совершенствования.
- Эффективность с точки зрения затрат и вычислительных ресурсов.
- QwQ-32B бросает вызов представлению о том, что большие модели всегда лучше, достигая сопоставимой производительности с DeepSeek-R1 при значительно меньшем количестве параметров.
Слабые стороны:
- Возможны проблемы с согласованностью языка и удобочитаемостью выходных данных, особенно во время обучения RL.
- Модель может смешивать языки или неожиданно переключаться между ними, что может снизить четкость ответов.
- Иногда модель может входить в рекурсивные циклы рассуждений, что приводит к длинным ответам без окончательного ответа.
- Требуются дополнительные меры безопасности для обеспечения надежной и этичной работы.
- Модель может быть не так хороша в задачах, требующих общего смысла и понимания нюансов языка.
- Модель может предоставлять дополнительную ненужную информацию, что иногда может приводить к ошибкам.
- В "Strawberry Test" модель не смогла точно подсчитать буквы и их позиции.

Вывод
QwQ-32B - это многообещающая новая большая языковая модель, которая бросает вызов традиционным представлениям о соотношении размера и производительности. Ее открытый исходный код, высокая эффективность и способность к самообучению делают ее ценным инструментом для исследователей и разработчиков. QwQ-32B имеет потенциал для дальнейшего развития и может внести значительный вклад в развитие искусственного интеллекта.
Команда Qwen рассматривает QwQ-32B как первый шаг в масштабировании RL для повышения возможностей рассуждений и стремится к дальнейшему изучению интеграции агентов с RL для долгосрочных рассуждений. «По мере того, как мы работаем над разработкой следующего поколения Qwen, мы уверены, что сочетание более сильных базовых моделей с RL, основанным на масштабируемых вычислительных ресурсах, приблизит нас к достижению искусственного общего интеллекта (AGI)», - заявила команда.
QwQ-32B знаменует собой значительный шаг к более доступному и эффективному ИИ, демонстрируя, что инновации могут приходить в меньших, более гибких пакетах, и прокладывая путь к будущему, где мощный ИИ доступен каждому.